Introduction
Halite is an annual A.I. competition hosted by Two Sigma where players of all skill levels compete in a game using any number of programming techniques. Each year the game boasts a shiny new design and is governed by a completely new rule-set, making the challenge engaging and interesting for newcomers and veterans alike. This year’s competition emphasized gathering resources in both 2 player and 4 player games.
My submission this year was a machine learning-based bot that learned to imitate top players. After attempting to imitate a number of different players, I found most success with ReCurse, and my final bot is a mimic of ReCurse.
This year, like every year, I look to Halite as an opportunity to practice my ML skills, and try methods that are new to me, creative, or a little crazy. I find ML very interesting because, to me, it’s a very creative process. It’s a little like building with Legos or painting a picture. You develop an intuition for all these small but elegant building blocks, and you can assemble them in very interesting and powerful ways. Coupled with some math and stats, ML is both a fascinating science and a very creative art.
At first glance, this year’s Halite looks like a simple image recognition problem, but it is much more subtle and interesting than that (and much more challenging!). Different maps sizes, different numbers of players, local decisions (moving to an adjacent square), global decisions (whether to build a ship), the fact that the game wraps along the edges, long range interactions (where is the nearest dropoff, or where are the largest piles of halite), should the game be handled stateless or not, etc., were all unique and difficult challenges that needed consideration and addressing in order to build a useful, or even highly competitive bot. Although I could spend hours talking about all the observations and lessons learned in my ML journey in this year’s competition, I keep the descriptions below rather succinct, and I hand-wave away a lot of the details. There were many small decisions that as a whole influenced the final form of my approach, but can be broadly categorized into three main components. The three components being the data, the model architecture, and the training process.
Data
When it comes to ML, the data and how the data are processed are of course both extremely important. There were two data streams in the game that required processing and featurization: (1) the 2D frames representing the game board, and (2) 1D features for all other game state information, including time till end, player halite, etc.
Below I show a sample game frame and the several channels that I featurize then stack together to form the 2D input that is fed into the network.

Figure 1: The 2D feature maps that are fed into the network.
Top left: a snapshot of a game shown in the Halite visualizer is provided for reference (not fed to the network)
Feature maps, from left to right:
Top row: halite content of each cell, which cells contain a ship (white are mine, black are opponents), the amount of halite carried by each ship
Bottom row: locations of shipyards, locations of dropoffs, ships that are completely full, ship ids.
I opted to include ship ids because I felt that it was likely that at least some bots would sort their ships before assigning moves, which meant that whether a ship moved to a particular cell or not was dependent on its ID relative to other ships. In the end I do not know how much this feature actually helped (or hurt), but I provided it anyway just in case.
One thing to note is that I did not disambiguate opponents in 4 player games. As you can see in Figure 1 (top row, third from left) all the opponents are black and are not assigned unique values/channels. This simplified the data somewhat, but including explicit player information could be an important feature and is something that should be explored.
I decided to keep shipyards and dropoffs in different channels. Although they virtually serve the same purpose, the important distinction is that new ships originate from the shipyard location, so it was important to identify where those new ships would be coming from. Since I center all the frames according to shipyard location, I could probably have gotten away with adding the shipyard to the dropoff layer and excluding the whole extra shipyard channel, but it seemed like only a small benefit (if any) could be achieved with the simplification, and I decided to play it safe and keep shipyards explicit.
All frames were centered relative to my shipyard, and padded to 128×128 pixels. Padding was performed with the wrapped game board in mind by extending edges with slices of the respective opposing ends. Although convolutions are well suited to operating over images of different sizes, I chose to pad all frames to a fixed size, regardless of map size, for two reasons. The first is that it made batching data for training a lot more straightforward since I could simply include any mix of frames from different map sizes in the same mini batch. The second reason is that in my architecture (described later) I utilize a U-net shaped design that provides a 1-dimensional latent game state at the bottom of the U-net and sharing parameters whilst deriving a 1D state vector for different map sizes would be less elegant (each size would require a different amount of down and up sampling) and may not perform as well. This latent state is combined with the latent representations of the 1D opponent and map features and is used to predict whether a ship should be constructed or not, and to propagate the rest of the features and the overall game state upwards to the individual cells.
Data Pipeline
Two Sigma graciously provided access to game replays through their API, which made it possible to download large volumes of completed games that can then be used in training models. At the very beginning of the competition I invested significant time into developing a decent data pipeline long before I even starting thinking about coming up with fun architectures (I saved dessert for last!). I set up a cron job that ran every night, and downloaded all gold-level-and-above replays from the day before and indexed them. The indexing process iterated through all downloaded games and compiled meta information such as which players and versions were present in the replays so that during training I can load the index and quickly filter down to games that I was interested in. Near the end of the competition I was storing around 200GB of replay data on my hard disk, and ended up needing to purge old replays to allow space for the days’ replays. Though I could have kept a copy of the leaderboard and removed games with only players below a certain rank to make the data load much lighter, but I didn’t get around to doing this.
When it came time to training a model, I’d take the subset of the index that I filtered down, and then randomly sample replays to train over. There were two data balancing issues that I kept in mind when processing replays. The first was that although a replay may contain 400 frames, the frames are highly correlated, and it would not be wise training over mini batches that contained such highly correlated data. To mitigate this I employed multithreading to preprocess the data and load them into queues, one queue for each map size. A second thread and queue were then used to randomly load frames from different map sizes into a buffer so that when batches were sampled from the queue, they contained frames from different replays and from different map sizes.
Apart from dealing with maps that are different sizes and ensuring that batches are not highly correlated, there were yet other data challenges. The primary issue being that top players wouldn’t sit still! It is not wise to simply mash together data from different players, or even different versions of the same player, because the distributions of the data will be different and can completely ruin the learning process. With top players frequently submitting new bots, most bot versions only had a few hundred games at most (except for some players like TheDuck that had many more games, but had their own challenges related to maintaining a state, which I address later). This meant that I needed to be able to train a model using only a handful of replays per map size and number of players. To work around the low data problem, I employed a technique called multitask learning. The general idea is that I can present to the network several different streams of data (each stream a unique player/version) and share as many parameters in the network across players as possible. This way the network can learn general patterns such as which areas contain high concentrations of halite, which direction is the closest drop-off, nearby formations of enemies, etc., and benefit from a larger collection of data contributing to the learning of those shared parameters. Then, deeper in the network near the output, I can branch off small sections of unique parameter sets that are only used to learn a specific player/version, allowing for these branches to focus on a specific bot with a consistent data distribution whilst also helping the overall network become less susceptible to overfitting, because of the shared parameter. In my training script I made it easy to add or remove players, and I experimented with a variety of different players to include during training. The final model relied on a combination of replays from Teccles, SiestaGuru, Cowzow, and ReCurse.
To prepare the data for training, I parsed the replays (provided in json format) into numpy arrays. Once the features were all processed, these were stacked to give arrays of shape: map_size x map_size x 7, where 7 is the number of feature layers I generated. Opponent, map, and other meta information were also processed and included as features. These features included information about how long until end of the game, map size, number of players, player halite amounts, etc.
Architecture
Shown below is a simplified sketch of the architecture. The design is roughly inspired by U-net style segmentation architectures (Ronneberger et al., 2015), with the addition of residual skip connections rather than concatenated and convolved skip connections. Also worth noting is that I do not use any form of pooling, rather, downsampling is performed using strided convolutions. This enabled the network to learn how the downsampling should be performed in the parameters of the network, and is especially relevant in applications where relative location information is important to retain, which is usually discarded during the pooling process. Retaining location information is especially important in Halite where ships make movement decisions based on precise locations of neighboring entities.
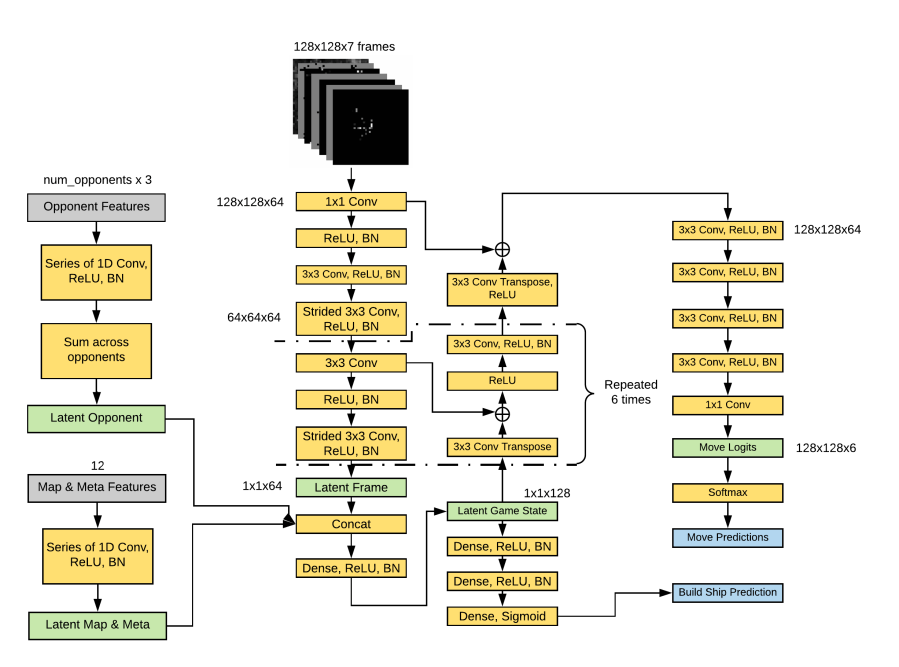
Figure 2: Model architecture. The model processes three streams of input data, combines their latent representations, then upsamples the representation until full resolution is restored. The network is fully end-to-end and provides predicted probability scores over 6 possible moves (left, right, up, down, still, build dropoff) for each ship, and also predicts whether a new ship should be built.
Although the model appears parameter heavy at first glance, it is actually relatively lightweight. Early in my experimentation, my models were around 300MB in size (much larger than the 100MB bot size limit), but after significant refinement and optimization the final model weighed in at about 5MB. I was actually somewhat surprised that the model fit in the CPU compute and memory limitations of the game servers. The bot did time out a small percentage of the games, but seemed entirely due to the model occasionally taking too long to load at the beginning of the game, and not related to exceeding the 2 seconds per turn time limit. One advantage of a nearly pure ML approach is that the computation is very monolithic, and computation is virtually consistent irregardless of the map size, number of ships, or any other game condition.
Training
The final model trained overnight and was stopped after 72k training steps were performed. A total of 7 bot versions were included in the multitask learning process (spread over 4 different players), with 4 frames per version included in each minibatch, resulting in an effective minibatch size of 28 frames. After 72k steps, a total of 2 million frames were seen during training. Before training, a portion of replays for each map size and each player/version were reserved for validation, and were periodically used to test the model during training. Models were determined to be an improvement only if the loss of all players showed an improvement; this helped avoid issues where the model would start to overfit on certain players while still improving on other players.
During training, the learning rate was changed in a cyclic fashion (see Figure 3). This seemed to both increase the speed of convergence and also helped achieve lower validation loss. In the end, my final bot only trained for ~70k steps which was much shorter than many of my other experiment runs, and the LR only cycled a single time in this case, so it is hard to know what benefit if any this actually provided, and further experimentation here could be interesting.
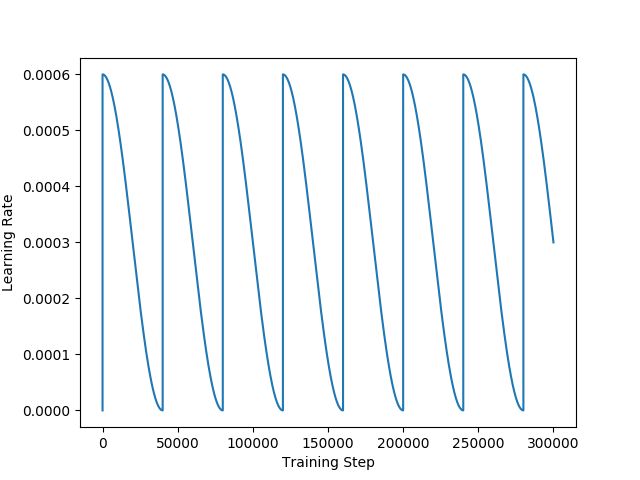
Figure 3: The learning rate changed cyclically over the course of training.
Since frames were padded (often significantly, for small maps), I did not want to include padding ships in the loss calculation and masked them out. Individual losses were calculated on a per-ship bases using cross entropy, comparing the predicted distribution over moves vs the correct moves as dictated by the players I attempted to mimic. Ship losses were averaged on a per frame basis, and the minibatch of frame losses were then averaged to provide an overall loss for computing the gradients with respect to the parameters. The loss also included a term for generating ships and terms for several auxiliary prediction tasks, with the loss function consisting of the form: moves_loss + 0.05 * generate_loss + alpha * [auxiliary tasks]. Feel free to check out the code for more details (link at the bottom). See Figure 4 for the training curves.
The model was implemented using TensorFlow and was trained using the Adam optimizer.

Figure 4: The validation performance of the multitasked players used to train the final model. Notice the “bump” from the learning rate being increased due to its cyclic adjustment.
For most players I generally saw validation losses in the 0.4-0.8 range, but unfortunately lower loss did not always translate to better performing bots (either locally or on the live game servers). Despite the ReCurse performance being somewhat worse (in terms of validation loss) versus some of the other players, it performed well most consistently, and was therefore the player chosen to govern all the moves made during the finals.
Hardware
Training was performed using a headless Linux desktop with 16 CPU cores, 32GB of RAM, and a single GTX 1080 Ti GPU. Experiment turnaround time was generally between 1-2 days using this setup. Given the model and batch size of the final bot, nearly the full 11GB of GPU RAM were utilized, and an equivalent or larger card is recommend for those interested in running the code.
Once training was complete, I had a choice of using using GPUs on the game server, or to stick with CPU. This became a trade off consideration very early in development that influenced my approach greatly. Although access to a GPU on the server meant more memory available and faster compute (to help with timeouts, and support larger, more complex models), this came at a great cost: fewer GPU workers available on the server meant far fewer games with your bot get player. This would make online evaluation take much longer, and results could be harder to interpret considering the frequency other players upload and change bots. But most significantly, this would also mean that the number of games the bot would play during finals would be decreased, which may have serious implications that could not be tested beforehand. So I opted to design a network that could fit in memory and be computed on the CPU within the 2 seconds per turn time limit, and ultimately run my bot on the server like everyone else. Although I’m happy with how it turned out, and for the challenge and learning experience it was to perform deep learning under such constraints, but I would love to see improved access to GPUs in future competitions. [Correction: I learned later that GPU workers were increased sufficiently during the finals and game rates likely wouldn’t have been a problem. Though, the issue of slow game rates before the finals, resulting in slower feedback vs CPU workers was still a concern.]
Post Mortem
During experimentation, I encountered a rather common (and frustrating) issue for many bots that I have yet to fully resolve in my method. That is, in many cases, even when achieving low validation loss during training, the bot, when played, would have a tendency to get stuck. Ships would move just fine, often in a very convincingly strong way, then out of no where they’d just freeze, and not move for the rest of the game. When other ships got near frozen ships, they’d also freeze, ultimately disabling the bot completely. This happened most frequently around dropoffs, and also in areas where it appeared that ships were considering building a new dropoff, or in other high traffic areas. At first I thought it might be an overfitting issue, but the behavior was definitely more pronounced and more consistent with certain bots, and virtually non-existent for others. I also thought it strange that it happened most often after the game had progressed for a while, and not happen immediately at the beginning. About half the competition I attempted to address this one issue and devised strategies to overcome it through the learning process. For example, I augmented the loss to predict which cells would contain a ship after moves were made, hoping that the model would emphasize cells with high probability of containing a ship (such as a dropoff surrounded by my turtles full of halite) instead of just prediction individual ship moves directly, but this didn’t seem to help much.
Coming into the competition I made a major assumption: that bots were primarily stateless, that is, bots would move deterministically given only the current frame, and did not rely on information from past frames in making decisions. Although I knew this could be a weak assumption, it was a necessary one. Not only did it drastically simplify the data processing and the model, but I knew that it would be very unlikely that I could design a sufficiently powerful model that could incorporate states, such as through an RNN, that would fit within the server’s compute constraints. Also, it makes having enough data for training much harder, because instead of looking at 40,000 individual frames as training samples, for example, it would become 100 full games that would need to be processed as a single datapoint.
Alas, this was very likely indeed the grand challenge in mimicking top bots. In the days proceeding the final submission day, top players released their bots and discussed their strategies, and many utilized at least some extent of a state, with some relying on it quite extensively. Particularly teccles (the #1 bot) mentioned that their bot observes players in the early game and then makes decisions based on those earlier observations. This could be exactly what was causing my issues with early games being strong before the bot getting stuck in the mid-game.
[Experimental] RL for player selection
My original intention was to pursue reinforcement learning methods. The plan was to first establish a decent learning model and algorithm through supervised learning, then push the model further either through optimization through RL, or learning completely from scratch through self play. Given the difficultly in developing successful RL agents, I like to first validate through supervised learning that my model is well suited to the task, and can adequately represent the state of the game and make successful decisions based on that state. In the end, the game was a much harder learning problem than I had anticipated, and I ended up committing to a purely supervised learning approach. Although I wasn’t able to fully formulate a reinforcement learning solution in time, in the final days I experimented with RL optimization over my SL bots.
One of the advantages of the multitask learning approach, is that my bot learned to mimic multiple players using a single model. For example, my final model performed best when set to ReCurse mode, and played exclusively as ReCurse in the finals, but it could also play rank ~13 versions of both SiestaGuru and Cowzow. Ideally, RL would be used to optimize moves across all ships. But as a very simple RL exercise, I realized that choosing players is a much small action space (only 3 actions to choose from: play this frame as ReCurse, SiestaGuru, or Cowzow). This meant that given the Latent Game State (see Figure 2 above), I could optimize over which player I should use to govern all my ships for a particular frame. In theory, if a particular player performed very well in the early game, but another player is better at the end game, or different strengths on different map sizes or halite distributions, the RL algorithm can help learn how to make those selections to hopefully learn a bot that can outplay any individual bot. I’m in the processes of performing the analysis over my most recent optimization run.
<more to come soon>
What’s next?
A machine learning bot has yet to make a top 10 finish in the history of Halite, but I feel we are getting close to making that a reality (only getting edged out this year by a fraction of a mu), and I’m looking forward to what’s in store for next year. Near the end of the competition I felt like I was experiencing a really flat plateau where further improvement through supervised learning was only incremental at best. I eked out all I could with a CPU-bound, stateless mimic bot. Now that the competition is over (and after a little bit of a Halite break), I hope to revisit my approach and re-attempt an RL-based solution that incorporates state and see if I can make any further improvements. Perhaps next year a machine learning bot that is stateful, improved through self-play, and takes advantage of available GPU server workers may very well make it into the top 10. Congrats to all the winners, and thanks all for the great community and well-run competition, it’s been fun!
